MPEG
Uno standard per la compressione di immagini in movimento
Luigi Filippini
Sommario:
In questo articolo si evidenziano le caratteristiche tecniche dello standard MPEG per la compressione di sequenze di immagini.
Vengono presentati gli algoritmi ed i procedimenti in esso utilizzati, valutate le sue prestazioni e descritte le applicazioni, attuali e future, derivanti dalla accettazione di questo standard in campo accademico ed industriale.
Introduzione
Da diversi anni i sistemi per la trasmissione di immagini in movimento hanno assunto una notevole importanza, la ampia banda necessaria per tali trasmissioni ha pero' frenato lo sviluppo di sistemi digitali per il loro trattamento.
Questo ha favorito la accettazione di standard analogici per la videoregistrazione e diffusione di filmati ed animazioni che, pur non presentando inconvenienti per la diffusione televisiva, non sono di fatto utilizzabili in campo scientifico.
La realizzazione di filmati analogici non consente infatti di archiviare un numero elevato di animazioni ed accedere in maniera efficiente alla singola animazione o singolo fotogramma.
Un filmato, una volta realizzato, non e' piu' modificabile e la sua duplicazione comporta un degradamento significativo della qualita' delle immgini.
Soprattutto, malgrado le reti di trasmissione abbiano avuto un notevole sviluppo, non e' tuttora possibile trasmettere attraverso di esse animazioni e filmati di buona qualita' e questo rende difficile la collaborazione fra gruppi di persone in differenti aree geografiche.
Lo standard MPEG consente una efficiente compressione di una sequenza di immagini permettendone quindi la memorizzazione, in formato digitale, sugli attuali supporti magnetici ed ottici e la trasmissione attraverso reti digitali.
Sistemi video digitali
I sistemi di trattamento ed elaborazione digitale di un segnale video si differenziano sostanzialmente in funzione della frequenza con la quale i vari fotogrammi vengono visualizzati e delle dimensioni, in punti, di tali immagini.
Lo standard CCIR-601, ampiamente adottato da tutti i fabbricanti di apparecchiature video digitali per il mercato USA, prevede che le immagini trattate siano di 720x243 punti e vengano visualizzate ad una velocita' di 60 campi al secondo.
Dato che un campo e' costituito dalle sole righe pari o dispari di un fotogramma ed i campi vengono alternati ed interallacciati, visualizzando ogni campo per 1/60 di secondo si ottiene una sequenza di immagini alla frequenza di 30 fotogrammi al secondo.
I due canali di crominanza vengono decimati con rapporto 2:1 lungo la direzione orizzontale, e ridotti pertanto a 360x243 punti a 60 campi al secondo, e ancora vengono visualizzati interallacciati.
Questo tipo di decimazione dei canali di crominanza, molto usato in campo televisivo, e' chiamato 4:2:2 ed indica la frequenza di campionamento utilizzata per Y, U e V espressa in rapporto alla frequenza di riferimento di 3,365 MHz.
Purtroppo per trattare questo genere di segnali occorrerebbe un sistema con una banda capace di trasmettere un flusso di bit dell'ordine di
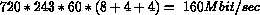 Tale banda supera di diversi ordini di grandezza la larghezza di banda usualmente disponibile su reti di trasmissione digitale, dell'ordine di 10 Mbit/sec, e, soprattutto, e' molto superiore al data rate dei dispositivi di input e output, tipicamente CD, DAT o dischi magneto-ottici, attualmente dell'ordine di 1,5-2 Mbit/sec.
Tale banda supera di diversi ordini di grandezza la larghezza di banda usualmente disponibile su reti di trasmissione digitale, dell'ordine di 10 Mbit/sec, e, soprattutto, e' molto superiore al data rate dei dispositivi di input e output, tipicamente CD, DAT o dischi magneto-ottici, attualmente dell'ordine di 1,5-2 Mbit/sec.
Lo standard MPEG
Il comitato MPEG (Moving Picture Expert Group) ha concluso, alla fine del 1991, il ``Committee Draft of Phase I'', comunemente chiamato MPEG I, che stabilisce la struttura di un bit stream per audio e video digitali compressi che rientri all'interno del data rate di 1,5 Mbit/sec.
Pertanto un segnale conforme allo standard MPEG I puo' essere memorizzato sugli attuali dispositivi ed essere trasmesso attraverso le attuali reti di trasmissione digitale, sia locali che geografiche.
Il Draft si divide in tre parti : Video, Audio e Sistemi. Le prime due (ISO 11172-1 e ISO 11172-2) specificano il tipo di compressione da effettuare sui segnali audio e video mentre la terza (ISO 11172-3) specifica come deve essere effettuata la integrazione fra i due, consentendo pertanto la sincronizzazione fra audio e video.
Le tecniche che vengono utilizzate per la compressione, decimazione dei canali di crominanza, trasformata discreta coseno, quantizzazione dei coefficienti e compressione di Huffman, derivano in gran parte da quelle proposte dallo standard JPEG (Joint Photographics Expert Group) per la compressione di immagini fisse.
Tale standard, per i buoni risultati di compressione che si riescono ad ottenere con immagini a colori o in toni di grigio, e' molto diffuso nella comunita' scientifica ed utilizzato in molte apparecchiature nei campi della fotografia ed elaborazione delle immagini.
Il segnale in ingresso per lo standard MPEG I, chiamato SIF (Source Interface Format), equivale ad un segnale CCIR-601 decimato con rapporto 2:1 in orizzontale, 2:1 lungo l'asse dei tempi ed ancora 2:1 lungo l'asse verticale dei due canali di crominanza. Qualche linea viene ulteriormente eliminata per fare in modo che le dimensioni dell'immagine siano multiple di 8 e 16 e semplificare cosi' i calcoli successivi.
Questo ci porta ad una risoluzione per il formato SIF di 352x240 punti a 30 fotogrammi al secondo.
In Europa la frequenza di visualizzazione, per gli standard PAL e SECAM, e' di 50 campi al secondo. Poiche' pero' il numero di righe in un campo e' superiore (288 anziche' 243) abbiamo che la risoluzione del SIF europeo e' di 352x288 punti a 25 fotogrammi al secondo.
Dal punto di vista del bit rate i due formati sono esattamente equivalenti essendo entrambi costituiti dallo stesso numero di punti al secondo (visto che 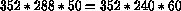 ), pertanto in seguito considereremo solo il formato SIF US.
), pertanto in seguito considereremo solo il formato SIF US.
Abbiamo visto che nelle immagini a colori in ingresso nel formato SIF, che considereremo gia' convertite nello spazio YUV, i due canali di crominanza (U e V) vengono ulteriormente decimati con rapporto 2:1, ottenendo quindi delle immagini di 352x240 punti per Y e 176x120 per U e V.
Questo fatto non comporta un degradamento percepibile delle immagini se queste sono naturali (ad es. fotografie), ma purtroppo tale degradamento puo' essere visibile se le immagini sono generate sinteticamente (ad es. immagini ed animazioni generate al computer).
Tuttavia la qualita' generale dell'immagine non decade comunque in maniera particolare.
Il bit rate di una sequenza di immagini SIF non compresse e' quindi :
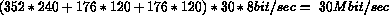
e pertanto ancora molto al di sopra dell'obbiettivo prefissato.
Lo standard prevede pertanto l'utilizzo di alcune sofisticate tecniche per eliminare la ridondanza dei dati in ingresso e diminuire quindi il bit rate di almeno un ulteriore fattore 20.
Motion compensation
La maggior parte dei fotogrammi di una sequenza e' in genere molto simile, le differenze fra un fotogramma ed il successivo in genere sono dovute solo a traslazioni di parti di esso.
Ha quindi senso pensare di evitare di trasmettere le parti che non sono cambiate e di trasmettere, per quelle che si sono spostate, solo il verso e l'entita' dello spostamento (motion vector).
Nello standard MPEG esistono tre tipi di fotogrammi : fotogrammi che vengono codificati singolarmente senza nessun riferimento ad altri (Intraframes o I frames), fotogrammi che vengono predetti sulla base di un frame di tipo I (Forward predicted frames o P frames), e fotogrammi che vengono ottenuti interpolando fra un frame I ed un frame P (Bidirectional frames o B frames).
In MPEG quindi la predizione di un fotogramma puo' essere fatta considerando sia la storia passata (I frames) che quella futura (P frames), il processo e' schematizzato nella figura :
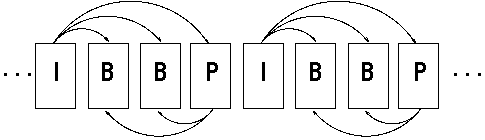
In sostanza come primo passo viene generato un frame I considerandolo come una singola immagine fissa.
Per il calcolo del motion vector e la predizione del frame P si considerano i punti all'interno di blocchi 16x16 (macroblock) nel canale di luminanza Y e nei corrispondenti blocchi 8x8 nei canali di crominanza U e V.
Per ognuno di questi blocchi si cerca quello che ad esso si avvicina di piu' nell'ultimo frame I o P inviato, il verso e la direzione fra questi due blocchi identificano il motion vector.
Se si riesce ad individuare il motion vector, per specificare il blocco nel frame P che stiamo codificando bastera' indicare, oltre ovviamente al motion vector stesso, la differenza fra i punti dei due blocchi in esame.
Una volta codificato un frame I ed uno P si possono codificare i frames B compresi fra essi.
Allora si esaminamo i macroblocks dei fotogrammi compresi fra il frame I e quello P cercando per ogni blocco quello a lui piu' simile nel frame I (quindi indietro nel tempo), quello piu' simile nel frame P (quindi avanti nel tempo) oppure cercando di fare una media fra il blocco piu' simile nel frame I e quello piu' simile nel frame P e sottraendo a questa il blocco da codificare.
Se con nessuno di questi tre procedimenti si ottiene un risultato soddisfacente si puo' sempre codificare il blocco come se facesse parte di un frame I ovvero senza riferimenti ai blocchi precedenti o futuri.
Quindi otteniamo logicamente una sequenza di frames del tipo :
I B B P B B P B B P B B I B B P B B P B B P B B I ...
in cui ci devono essere (codifica SIF US) al massimo 12 frames fra un frame di tipo I ed il successivo, mentre la successione di frames P e B e' libera.
Questo permette di poter avere un accesso casuale al flusso di immagini ogni:
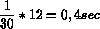
e di fare in modo che le immagini codificate non divergano troppe da quelle reali.
Naturalmente, visto che per poter decodificare i frames B occorre conoscere gia' il frame P successivo, la sequenza dei frames che vengono inviati dopo la codifica e' diversa da quella logica ed e' come segue :
TIPO I P B B P B B P B B P B B I B B P B B P B B P B B I ...
ISTANTE 1 1 1 1 1 1 1 1 1 2 1 2 2 2 2 2 ...
0 3 1 2 6 4 5 9 7 8 2 0 1 5 3 4 8 6 7 1 9 0 4 2 3 5 ...
Quindi le operazioni che si compiranno leggendo un flusso MPEG saranno sostanzialmente queste :
-
1) Lettura e decodifica del frame I(t=0)
-
2) Lettura e decodifica del frame P(t=3), visualizzazione frame I(t=0)
-
3) Lettura e decodifica del frame B(t=1), visualizzazione frame B(t=1)
-
4) Lettura e decodifica del frame B(t=2), visualizzazione frame B(t=2)
-
5) Lettura e decodifica del frame P(t=6), visualizzazione frame P(t=3)
-
6) Lettura e decodifica del frame B(t=4), visualizzazione frame B(t=4)
-
7) Lettura e decodifica del frame B(t=5), visualizzazione frame B(t=5)
-
8) Lettura e decodifica del frame P(t=9), visualizzazione frame P(t=6)
-
9) ...
Stadi di trasformazione : DCT
La codifica delle immagini attraverso i motion vectors di ogni macroblock con lo schema appena visto non riesce purtroppo a ridurre la quantita' di bit necessari per la rappresentazione delle immagini in ingresso.
Visto che pero', in genere, l'energia associata ai valori delle componenti Y,U e V di una immagine e' distribuita in una banda di frequenze abbastanza ridotta, ha senso applicare una trasformata ed aspettarsi di trovare informazioni spettrali in solo alcuni coefficienti.
Per ragioni di semplicita' si e' scelto di dividere l'immagine in blocchi di 8x8 punti ed applicare la DCT (Trasformata Discreta Coseno), un tipo di trasformata spesso utilizzata per la compressione di immagini.
La trasformata DCT bidimensionale puo' essere ottenuta applicando la DCT monodimensionale alle colonne ed alle righe di ogni blocco.
La sua espressione formale, in funzione del valore dei pixel del blocco 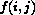 e dei coefficienti
e dei coefficienti 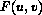 nel dominio della frequenza, e' la seguente :
nel dominio della frequenza, e' la seguente :
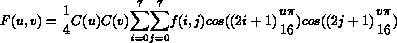
dove :
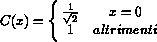
La trasformazione inversa della DCT bidimensionale e' invece espressa come segue :
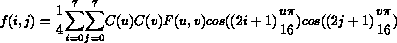
I coefficienti ottenuti, che sono in numero pari a quello dei punti del blocco, vengono organizzati in una matrice in modo che il valor medio, ovvero la componente continua, sia nell'angolo in alto a sinistra.
I coefficienti delle componenti alternate, come mostrato in figura :
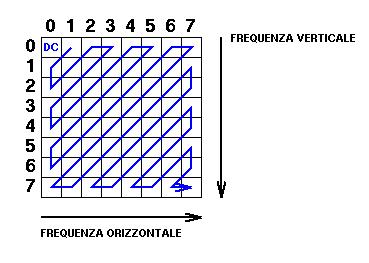
vengono invece disposti in ordine decrescente, con i valori piu' alti vicino alla componente continua, ed in modo da avere un numero di riga/colonna che cresce in funzione del valore della frequenza verticale/orizzontale.
Stadi di trasformazione : Quantizzazione
Come abbiamo detto il numero di coefficienti ottenuti per le varie componenti che hanno un valore nullo e' abbastanza elevato.
Per aumentare tale numero, introducendo naturalmente della distorsione e rinunciando a parte della informazione originale, tali coefficienti vengono quantizzati.
Per semplicita' viene usato un metodo di quantizzazione uniforme, usando pero' un passo diverso a seconda della posizione del coefficiente della DCT ed a seconda del tipo di frame.
Nei blocchi dei frames di tipo I vengono quantizzate separatamente le componenti alternate e continua secondo le seguenti espressioni :
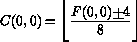
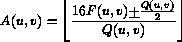
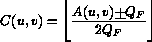
dove 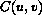 sono i coefficienti quantizzati, sono i coefficienti della DCT,
sono i coefficienti quantizzati, sono i coefficienti della DCT, 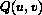 e' il passo del quantizzatore,
e' il passo del quantizzatore, 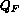 e' un parametro di quantizzazione ed il segno + viene preso positivo per positiva e negativo per negativa.
e' un parametro di quantizzazione ed il segno + viene preso positivo per positiva e negativo per negativa.
La quantizzazione inversa si ottiene ponendo :
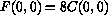
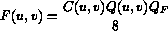
Mentre per i blocchi dei frames di tipo P e B il quantizzatore e' lo stesso per entrambi i tipi di componente e dato da :
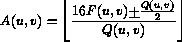
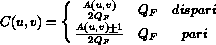
ed il segno + viene preso positivo per 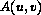 positiva e negativo per negativa.
positiva e negativo per negativa.
La quantizzazione inversa si ottiene da :
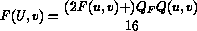
La quantizzazione e' la parte della codifica MPEG in cui si introduce l'errore maggiore dato che il cambiamento di scala di un coefficiente quantizzato comporta errori non recuperabili se il coefficiente in questione non e' multiplo del passo di quantizzazione.
Questa condizione non e', ovviamente, in genere rispettata.
Per il modo in cui viene fatta la quantizzazione l'entita' dell'errore dipende dalla posizione spaziale del campione, l'errore massimo che si puo' commettere e' pari alla meta' del passo di quantizzazione.
Se la quantizzazione viene fatta in modo troppo ``grosso'' le immagini ottenute appaiono segmentate e divise in grossi agglomerati, viceversa se viene fatta in maniera troppo ``fine'' si utilizzano piu' bit del dovuto per trasmettere informazione sostanzialmente solo legata a rumore.
Stadi di trasformazione : Codifica entropica
Abbiamo a questo punto ottenuto, per ognuno dei blocchi di ogni frame, una matrice nella quale i coefficienti delle componenti spettrali date dalla DCT sono ordinati, a zig-zag, in funzione della frequenza.
Sappiamo inoltre che, nella maggior parte delle immagini, sono le componenti a frequenza piu' bassa ad avere i valori maggiori mentre quelle a frequenza piu' elevata hanno in genere valore nullo.
Risulta pertanto naturale operare una codifica dei coefficienti di tipo RLE (Run Length Encoding).
I coefficienti delle componenti continue, in genere diversi da zero, sono codificati scrivendo il numero di bits significativi nel loro valore seguiti dagli stessi bit significativi.
I coefficienti delle componenti alternate, in genere uguali a zero, sono codificati scrivendo il numero di zeri consecutivi ed il primo valore non nullo.
I codici che si ottengono dalla codifica RLE vengono ulteriormente compressi con un codificatore di Huffman, scelto per la sua facilita' di implementazione in hardware, utilizzato in una veriante leggermente semplificata.
Per il funzionamento del codificatore di Huffman si rimanda alla letteratura ed alla bibliografia.
Prestazioni
Partendo da immagini originariamente in formato SIF e convertendole in MPEG si ottiene un fattore di compressione di circa 30:1.
La qualita' delle immagini che si ottengono e' sostanzialmente comparabile con quella delle immagini in ingresso.
Viceversa se le immagini originarie sono di qualita' superiore, ad esempio CCIR-601 o immagini RGB ottenute da un computer che vengono convertite in SIF, il fattore di compressione globale e' molto piu' alto, anche 100:1, ma il degrado di qualita' delle immagini e' molto piu' marcato.
Ad esempio per memorizzare un filmato di 165 frames in formato RGB a 352x288 punti, dato che ogni fotogramma occupa 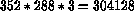 bytes, occorrono circa 50 Mbytes.
Lo stesso filmato, compresso in MPEG senza sacrificare troppo la qualita', occupa solo 1,1 Mbytes denotando quindi un rapporto di compressione di circa 50:1.
La trasmissione di tale filmato, supponendo un data rate di 1 Mbit/sec, avrebbe comportato un tempo di 400 secondi mentre la versione compressa puo' essere trasmessa in poco meno di 9 secondi.
bytes, occorrono circa 50 Mbytes.
Lo stesso filmato, compresso in MPEG senza sacrificare troppo la qualita', occupa solo 1,1 Mbytes denotando quindi un rapporto di compressione di circa 50:1.
La trasmissione di tale filmato, supponendo un data rate di 1 Mbit/sec, avrebbe comportato un tempo di 400 secondi mentre la versione compressa puo' essere trasmessa in poco meno di 9 secondi.
Uno dei punti piu' critici sta nel fatto che al codificatore e' lasciata una ampia liberta' di scelta sul tipo di frame da utilizzare e sul tipo di codifica da effettuare sui singoli macroblock.
Pertanto a parita' di sequenza di immagini in ingresso, ma al variare dei parametri del codificatore, si possono ottenere un gran numero di sequenze diverse, sempre ripettanti lo standard MPEG, ognuna con un diverso valore di compressione e diversa qualita'.
Oltretutto, benche' si stiano facendo molte ricerche in questo campo, vi e' un forte interesse da parte dei costruttori di hardware a mantenere riservati i risultati di queste per poter acquisire vantaggi competitivi nella fabbricazione di codificatori su singolo chip.
Quindi, anche utilizzando codificatori software, il tuning dei vari parametri e' particolarmente critico e le prestazioni che si ottengono variano molto a seconda della configurazione o delle immagini in ingresso.
In generale, ottenendo un risultato di qualita' media, ci si puo' aspettare che i frames di tipo I vengano compressi di un fattore 10:1, quelli di tipo P di un fattore 30:1 e quelli di tipo B di 60:1.
I filmati MPEG attualmente disponibili hanno rapporti di compressione variabili fra 30:1 sino a 100:1.
Applicazioni
Le applicazioni della compressione di immagini in movimento sono molteplici e sono, per la maggior parte, orientate verso l'elettronica di consumo (videogiochi, videotelefono e videoconferenze, educazione a distanza, ecc.).
Nel campo scientifico la possibilita' di codificare filmati ed animazioni in files di dimensioni ridotte consente nuove possibilita' di collaborazione fra vari centri di ricerca.
Molti centri stanno gia' organizzando delle digital galleries che rappresentano le ricerche effettuate ed i risultati ottenuti con dei brevi filmati MPEG. Ad esempio NCSA (National Center for Supercomputing Applications) presenta le sue attivita' nello ``Science Theater'' con una serie di filmati MPEG, accessibili attraverso la rete Internet, che rappresentano dei lavori nei campi della fluido dinamica, astrofisica e visualizzazione volumetrica.
E' gia' possibile inviare dei filmati MPEG attraverso i vari sistemi di posta elettronica dato che lo standard MIME (Multipurpose Internet Mail Extension) consente di incorporare blocchi di video MPEG all'interno di un messaggio. Inoltre MPEG e' supportato dal sistema WWW (World Wide Web) e dal browser xmosaic, sotto X windows, per la ricerca ipertestuale di informazioni sulla rete Internet.
Sulle USENET news sono comunissimi i posting di filmati MPEG nei gruppi dove un tempo venivano scambiate immagini fisse in formato GIF o TIFF.
Sviluppi futuri
Il comitato MPEG e' gia' al lavoro per la definizione dello standard MPEG II il cui scopo e' di definire un bit stream per audio e video codificato in 3-15 Mbit/sec.
Nella riunione che si e' tenuta a Sidney, il 2 Aprile 1993, e' stato stilato il primo draft del ``Video Main Profile'' in cui si sottolinea la convergenza di interessi nello standard MPEG di diverse industrie nei settori della diffuzione televisiva (via cavo, via satellite e terrestre), della HDTV (televisione ad alta definizione), delle telecomunicazioni, dell'informatica e della elettronica di consumo.
Per garantire uno sviluppo uniforme dello standard partecipano alla definizione di MPEG II anche organismi come il ``CCITT Study Group XV'', gruppo di studio per codifica video su reti ATM (Asynchronous Transfer Mode), ed altre istituzioni internazionali.
Il nuovo standard, pur rimanendo compatibile con MPEG I e permettendo interoperabilita' con lo standard H261 per le videoconferenze su linee telefoniche, permettera' di ottenere una migliore qualita' delle immagini e supportera' il formato video interallacciato.
Fra le nuove applicazioni supportate, la possibilita' di trasmissione via cavo con un bit rate fino a 15 Mbit/sec apre vastissimi orizzonti alla televisione interattiva ed alla fornitura diretta di servizi multimediali.
Poiche' si prevede di avere entro Novembre 1993 il draft con il nuovo standard, molte industrie, facenti parte del comitato MPEG, hanno gia' annunciato, per i primi mesi del 1994, nuovi prodotti che lo utilizzeranno.
Nel campo scientifico, poiche' lo standard e' ancora in definizione, e' molto alto il numero di ricercatori che studiano gli effetti delle varie tecniche di compressione sulla qualita' delle immagini ottenute.
Molti lavori vengono inoltre realizzati nello studio di nuovi algoritmi per effettuare la DCT o nello studio di nuove trasformate che garantiscano migliori prestazioni al coder MPEG.
Quasi tutti i produttori di componenti elettronici , ad esempio Texas Instruments, Cypress Semiconductors, Motorola, Xing Technology/Analog Devices, Sony e C-Cube, hanno gia' annunciato la disponibilita' di codificatori/decodificatori MPEG su singolo chip ed importanti accordi, come ad esempio SGS-Thomson e Sanyo, sono stati fatti per incorporare questi dispositivi in apparecchi elettronici destinati al grande pubblico.
C'e' quindi da prevedere che, con lo sviluppo delle reti di trasmissione digitale e l'introduzione del sistema B-ISDN (Broad Band Integrated Services Digital Networks), i meccanismi di compressione di immagini in movimento avranno una importanza sempre maggiore e saranno sempre' piu' integrati nelle apparecchiature di uso comune come televisione, video-telefono e personal computer.
Bibliografia
- 1
- Eric Hamilton,
``JPEG File Interchange Format, Version 1.02,'' September 1, 1992.
- 2
- W. A. Chen, C. Harrison, and S. C. Fralick,
``A Fast Computational Algorithm for the Discrete Cosine Transform,''
IEEE Trans. Commun., vol. COM-25, No. 9, pp. 1004-1011,
September, 1977.
- 3
- Byeong G. Lee, ``A New Algorithm to Compute the Discrete
Cosine Transform,'' IEEE Trans. Acoust., Speech, Signal
Processing, vol. ASSP-32, No. 6, pp. 1243-1245, December 1984.
- 4
- Ephraim Feig, ``A fast scaled-DCT algorithm,''
SPIE Image Processing Algorithms and Techniques, vol.
1244, pp. 2-13, 1990.
- 5
- Atul Puri and R. Aravind,
``Motion-Compensated Video Coding,'' IEEE Trans. on Circuits
and Systems for Video Technology, vol. 1, No. 4, pp. 351-361,
December 1991.
- 6
- David A. Huffman,
``A Method for the Construction of Minimum-Redundancy Codes,''
Proc. IRE, pp. 1098-1101, September 1953.
- 7
- Didier Legall,
``MPEG - A Video Compression Standard for Multimedia Applications,''
Communications of the ACM, vol. 34, No. 4, pp.
47-58, April 1991.
- 8
- MPEG,
``MPEG Video Simulation Model Three (SM3),'' Draft #1, MPEG90.
- 9
- MPEG,
``Coding of Moving Pictures and Associated Audio for Digital Storage
Media at up to about 1.5 Mbits/s. Part 2, Video.'' MPEG 91/185 (Santa
Clara).
- 10
- Andy C. Hung,
``PRVG MPEG-CODEC Manual'' Portable Video Research Group
(Stanford).
- 11
- K. Patel, B.C. Smith, L.A. Rowe,
``Performance of a Software MPEG Video Decoder'' CS Division-EECS,
Unevrsity of California (Berkeley)