Antonio TiccaCRS4
Centro Ricerca e Sviluppo Studi Superiori in Sardegna
Via Nazario Sauro 10, Cagliari,
tel 070 2796253, fax 070 2796283
e-mail mav@crs4.it
Il seguente articolo analizza le problematiche connesse alla progettazione di un sistema ipertestuale aperto operante in ambienti distribuiti di tipo wide-area e descrive uno strumento sviluppato al CERN di Ginevra (World Wide Web) e adottato al CRS4 che, utilizzando le tecniche disponibili, ha permesso la nascita di una struttura di informazioni di tipo globale. Sono descritti gli obiettivi, i modelli dei dati e i protocolli necessari per implementare la rete (web).
Parole Chiave
Information retrieval, Hypertext, World Wide Web
Introduzione
Negli ultimi tempi si é assistito ad un notevole aumento dei problemi
connessi all'evoluzione dei vari sistemi informativi. Uno di questi coincide
con la sempre maggiore produzione di libri, articoli, studi informali e
reports. A questo aumento di produzione di informazione su scala mondiale,
corrisponde infatti la conseguente necessitá di immagazzinare e ritrovare
in maniera condivisa tale informazione in tempi ragionevolmente brevi.
Fortunatamente anche i cambiamenti nel modo di trattare l'informazione sia in ambiente locale che distribuito sono notevoli, grazie ad un'evoluzione dell'architettura degli strumenti di calcolo ed al potenziamento delle capacitá di trasferimento delle reti di interconnessione.
La spinta verso un cambiamento, nell'ottica di un miglioramento dell'utilizzo delle risorse, arriva prevalentemente dal mondo scientifico che per sua stessa natura richiede la condivisione delle esperienze e dei risultati delle ricerche.
Questa esigenza di condividere la massa delle informazioni scientifiche attraverso una rete distribuita di tipo wide-area (Internet) che ormai collega tutto il pianeta, ha portato diversi centri di ricerca a studiare sistemi di information retrieval ad ampio raggio. Questo allo scopo di superare le barriere geografiche che impediscono di fatto le collaborazioni fra i gruppi scientifici, e di accelerare lo scambio di informazioni attraverso l'uso di protocolli standard.
Questi progetti si avvalgono del fatto che molte informazioni disponibili in rete sono di libero accesso e che le strutture a disposizione della comunitá scientifica sono tali da permettere uno scambio dei dati in maniera relativamente veloce.
Tuttavia la maggior parte delle informazioni disponibili on-line, sono accessibili all'utente generico, solo dopo aver superato barriere che riguardano: conoscenza dell'indirizzo di rete della macchina sulla quale le informazioni risiedono, modalitá di accesso al sistema, tipo dei terminali, sintassi dei comandi e cosi via; é dunque indispensabile disporre di strumenti che aggirino tali ostacoli e siano in grado di accedere alle informazioni di pubblico dominio in modo diretto.
Il supporto naturale per tale scambio di informazioni è come giá detto la rete Internet.
Internet puó logicamente essere vista come una rete di interconnessione composta da migliaia di nodi e centinaia di migliaia di utenti sparsi in tutto il mondo. Essa permette l'accesso ad una enorme quantitá di risorse, servizi ed informazioni, utili per una larga maggioranza di suoi utenti, accessibili peró solo a coloro che hanno maturato una certa esperienza nel muoversi al suo interno. La capacitá di districarsi all'interno della rete implica la conoscenza dei luoghi nei quali le specifiche informazioni risiedono e quindi la possibilitá di recuperarle senza eccessiva perdita di tempo. Il problema infatti non é tanto ottenere informazioni dalla rete quanto determinarne la loro locazione.
Ci si puó subito rendere conto, che implementare uno strumento automatico che consenta di recuperare i dati richiesti, in modo del tutto trasparente all'utente, costituisce un notevole passo avanti dal punto di vista del risparmio di tempo. Non é necessario conoscere né i protocolli di trasferimento né le locazioni delle informazioni dal momento che tutte queste funzioni sono prerogativa di tale strumento. I tools giá esistenti per il recupero delle informazioni in ambiente Internet (vedi archie, gopher, rn, ecc.) sono poco funzionali, se si considera che hanno accesso solo ad una parte relativa delle risorse in rete; inoltre bisogna considerare il fatto che ognuno di questi strumenti ha un proprio modo di rielaborare le informazioni e quindi di presentarle all'utente finale. Sorge dunque l'esigenza di costruire uno strumento che abbia non solo le funzionalitá di information retrieval e di browsing, ma anche una certa capacitá nel trattare qualsiasi tipo di informazione (testo, figure, immagini ed animazioni).
Internet non ha autoritá centrale; ciascun nodo ha un suo protocollo per la ricerca ed il recupero delle informazioni, e molti sono ancora in fase di sviluppo. La necessitá di rendere tutti questi sistemi capaci di effettuare una ricerca e una letura dei dati in maniera uniforme, a dispetto dell'eccessivo numero di protocolli usati dalle diverse piattaforme, porta alla logica conseguenza di creare uno standard per la identificazione univoca dei documenti. Poiché i nomi che identificano questi documenti vengono trattati in molti modi e da svariati protocolli, deve essere possibile un accesso globale anche quando questi ultimi evolvono.
Il corretto indirizzamento ai documenti (document naming) rappresenta, con tutta probabilitá l'aspetto cruciale nella progettazione di un sistema ipertestuale aperto. Esso si rivolge in particolare alla consistenza della sisntassi di un document name, attraverso il quale é possibile l'accesso al documento. Inoltre, dal momento che vengono utilizzati diversi protocolli per il reperimento dei documenti, deve essere possibile giá dall'indirizzo poter risalire, attraverso delle etichette (tags), al protocollo con il quale si effettua la ricerca.
Specifiche per la progettazione di sistemi ipertestuali.
Nella progettazione di sistemi per il recupero di informazioni di tipo
ipertestuale, bisogna tenere conto di una serie di specifiche che costituiscono
i punti cardine per la loro implementazione e per il loro funzionamento. Quando
si deve progettare un tale sistema ci si trova davanti ad una serie di domande
del tipo:
Vi sono inoltre altri tre importanti criteri decisionali da tenere in considerazione:
I sistemi ipertestuali in genere hanno avuto il loro maggior sviluppo nelle aree applicative di tipo comunicativo (per es. enciclopedie). Anche pubblicazioni di tipo centralizzato come help in linea, documentazione, tutorial si prestano bene ad una implementazione di tipo ipertestuale.
Una maggiore portabilitá di tali sistemi su un gran numero di piattaforme determina una loro piú ampia diffusione e un migliore utilizzo per cui, fin dalla fase di progettazione, si cerca sempre di studiare un prodotto finale che abbia queste caratteristiche.
Per quanto riguarda le tecniche di navigazione si possono individuare diversi modi con i quali accedere alle informazioni. Fra questi l'accesso navigazionale (seguendo i links) costituisce l'essenza stessa dell'ipertesto, che puó essere ottimizzato con una serie di facility che facciano si che le operazioni di recupero dei dati siano piú efficenti e meno confuse.
Per permettere all'utente di tener traccia dei documenti visitati ad esempio sarebbe utile implementare un meccanismo di history con funzioni tipo: home per richiamare il nodo iniziale; back per andare all'ultimo documento visitato in ordine cronologico; next per seguire il link immediatamente sucessivo del documento visitato e previous per l'operazione inversa.
Un ambiente grafico infine puó essere utile e puó essere costruito automaticamente, ma a quale livello ? Deve essere costruito dall'autore del documento, dal server, dal browser o da un daemon indipendente ?
Il progetto WWW [cite other:Bern92] nasce nei laboratori del CERN di Ginevra agli inizi degli anni '90. Il suo scopo é permettere l'accesso ed il recupero dell'enorme massa di informazioni disponibili in varie parti del mondo, attraverso i protocolli standard TCP/IP. L'idea base é quella di filtrare informazioni originariamente in forma non omogenea, memorizzate in grossi database per ricondurle in un formato standard chiamato HTML (Hyper Text Markup Language). In gran parte WWW risponde ai requisiti di un sistema di information retrieval descritti sopra, per cui puó benissimo servire da esempio per illustrare il modo di operare di tali sistemi.
L'utente di WWW ha a disposizione due modi di accesso all'universo di informazioni. Il primo consiste nel navigare attraverso gli hypertext reference, il secondo nell'interrogare con parole chiave (keywords) le unitá remote.
Un hypertext reference é rappresentato da un testo evidenziato o da un'icona su un'interfaccia grafica, oppure da un numero affiancato al testo su un'interfaccia on-line mode. Per selezionare il link, l'utente punta l'icona con il mouse o digita il numero da tastiera.
Il programma, al termine della sua ricerca, genera un documento reale o virtuale costituito a sua volta da uno stream di caratteri (plaintext) e da nuovi collegamenti (reference). Questo documento puó essere un qualsiasi file raggiungibile in maniera sequenziale (seguendo i links), oppure un file indice che contiene nuovi riferimenti ad altri documenti.
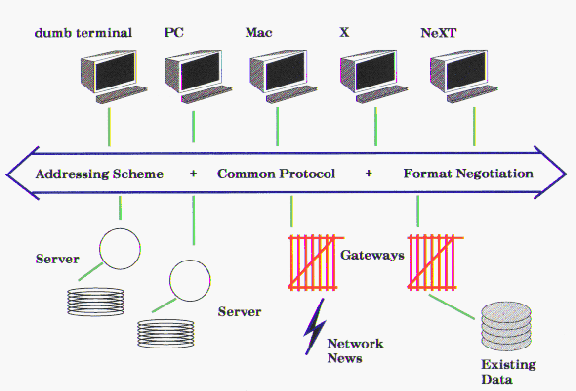
L'architettura perció sfocia in due programmi: un client browser ed un server, comunicanti attraverso la rete. Un bus logico di informazioni (information bus) connette fra loro i vari client (Fig.1).
Architettura di WWW
I requisiti principali di un information bus sono:
A questo livello di astrazione, l'universo concettuale di informazione é composto di documenti che possono essere o no oggetto di una ricerca (possono essere sia indici che testi normali). Il browser é libero di presentare i documenti e le relazioni fra essi in qualsiasi maniera scelta dall'utente. Il server d'altro canto é libero di generare questi documenti (virtuali o no) sia inviando dei files realmente esistenti, o generando ``al volo'' degli ipertesti virtuali in risposta alle richieste.
WWW attualmente é interfacciato con un certo numero di server che colloquiano attraverso i protocolli standard TCP/IP, mentre altri si servono di standard di trasmissione piú ad alto livello, come i protocolli Gopher, WAIS, Archie ed il nuovo protocollo HTTP (Hyper Text Transfer Protocol) [cite other:Bern91] creato apposta per il trattamento dei testi HTML.
Fra i protocolli standard citiamo:
Altri protocolli non standard sono in uso da sistemi sperimentali. Essi richiedono, per essere accessibili dai browser di WWW, il filtraggio delle informazioni attraverso dei gateways in modo che queste vengano ricondotte al formato HTML. Fra questi protocolli citiamo:
La potenza del sistema ipertestuale aperto si deve dunque non a protocolli complessi, ma alla univoca identificazione dei documenti all'interno della rete.
La formalizzazione ad alto livello del cosiddetto ``hypertext data model'' è basata sullo standard HyTime [cite other:GoldF] in seguito ad una modelizzazione concettuale dovuta a Dexter [cite other:Ha_Sw]. Il progetto WWW si rifá a questi due modelli definendo una sintassi concreta basata sullo stile SGML (Structured Generalized Markup Language) [cite other:SGML] che permette la formattazione dei documenti, siano essi liste strutturate, risultati di una ricerca, o semplici testi in maniera omogenea. Ogni applicazione client di WWW è in grado pertanto di effettuare un'analisi (parsing) di questo semplice formato (Fig.2) e di visualizzare direttamente le informazioni all'interno dell'interfaccia grafica.
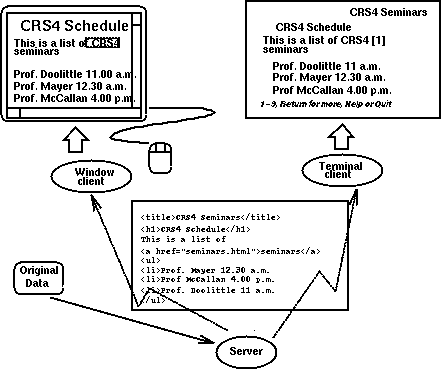
Lo schema illustra la codifica di un dato ipertestuale. I dati originali vengono filtrati per essere ricondotti in forma HTML e per poi essere passati alle routine di visualizzazione dei vari client browser. I link sono rappresentati da testo evidenziato (nel box) nell'interfaccia grafica, da un reference number nell'interfaccia on-line.
Nella fase pilota del progetto WWW, tutto ció che veniva richiesto era un solo formato di dati costituito appunto da HTML, ma nella seconda fase venne ammessa una negoziazione su diversi formati di dati fra client e server in modo tale che potesse essere permesso lo scambio delle informazioni e l'uso di diverse rappresentazioni riconosciute da entrambi.
La possibilitá di utilizzare una tipologia di informazioni eterogenee in un unico ambiente, ha portato quindi all'accrescimento della massa di informazioni grazie alla possibilitá di una facile inserimento di nuovi dati nella struttura.
Creare una rete (web) è relativamente semplice dal momoento che occorre solamente scrivere pochi file in formato HTML e creare i collegamenti fra loro. Questi ultimi non sono altro che indirizzi in forma UDI. Per recuperare i documenti, il programma attiva ad ogni richiesta la connessione con il server HTTP attraverso una chiamata, GET address, nella quale address è l'indirizzo del documento. Il server, in caso di successo (corretto indirizzamento e consistenza della richiesta), provvede al trasferimento del documento formattato, altrimenti invia un messaggio di errore. Sará poi compito del programma rielaborare il documento con la costruzione di un hypertext reference per ogni link trovato o la chiamata di un tool di visualizzazione grafica nel caso di un immagine.
Le operazioni precedentemente descritte valgono per il recupero di un qualsiasi file supportato da WWW, sia esso una news, un file gopher, wais e così via. L'analizzatore degli indirizzi (parser), contenuto nel programma, permette di selezionare in base allo schema di riferimento (tagging scheme) dell'indirizzo, il protocollo di trasferimento per quesl file, e di attivare infine la connessione con il server.
L'opportunitá di creare documenti con piccolo sforzo permette l'aggiornamento e quindi l'accrescimento del database con una velocitá maggiore rispetto ai metodi tradizionali, senza contare che l'accesso al mondo dell'informazione è personalizzabile grazie alla possibilitá di creare documenti indice (entry point) che puntino ai documenti di maggiore interesse.
La Fig.3 mostra come puó essere costruita una rete di informazione personalizzata utilizzando gli operatori descritti sopra.
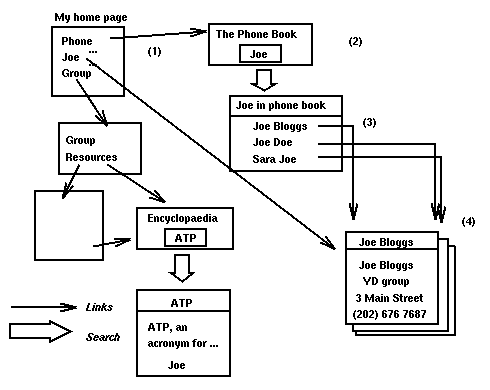
Una rete di links e indici. Il modello WWW accomuna la ricerca per indice e il collegamento per links. L'utente entra dalla home page (1) per anvigare attraverso la rete pubblica e privata. Indici come il phone book (2) sono rappresentati da documenti virtuali che accettano in ingresso una keyword. Il risultato è anch'esso un documento virtuale (3) che punta al documento trovato
Osserviamo che:
L'aspetto utile e significativo di tale architettura è che tutti i sistemi di informazione giá esistenti possono essere rappresentati secondo il modello WWW. Una lista strutturata diventa dunque una pagina di ipertesto, in cui ciascun elemento punta ad una destinazione differente. Lo stesso vale per una directory facente parte di un qualsiasi sistema gerarchico o cross-linked.
Il concetto dei links ``rinominabili'' o multi named all'interno della rete, sta a significare che tutte le operazioni di ricerca da parte dei vari search engines possono essere effettuati in modo diversificato.
Un programma client in generale funziona da interfaccia tra utente finale ed applicazione. Lo scopo di questo programma è appunto quello di fare in modo che l'interazione fra le due entitá sia immediata facilitando le chiamate ad uno o piú server.
Generalmente il colloquio con l'utente finale avviene attraverso l'uso di un'interfaccia grafica piú o meno sofisticata dalla quale è possibile interagire con il programma attraverso il mouse a la tastiera. Un'interfaccia utente a WWW, in generale lavora nel seguente modo:
Esistono diversi programmi interfacciati tra utente e WWW, ognuno dei quali propone soluzioni diverse di visualizzazione dati, ma che fondamentalmente hanno funzionalitá simili. Ricordiamo ad esempio TkWWW, realizzato in linguaggio TCL/TK, Viola, Midas e infine XMOSAIC [cite other:Andre93] implementato nei laboratori NCSA, University of Illinois (vedi Fig.4).

XMosaic
Integrazione di WWW con altri sistemi informativi
Il successo del progetto WWW ha portato diversi centri di ricerca a sviluppare nuovi gateway ad altri sistemi informativi. Un'esperienza di questo genere è stata portata avanti al CRS4, includendo nel progetto originale diversi gateway programs per il filtraggio di informazioni di tipo anagrafico (Phone Book) di local announcements (Event Schedule) e di electronic publishing (Electronic Preprints), mentre sono in progetto altre estensioni all'architettura di WWW con la creazione di vari server che consentano la gestione di mappe geografiche interattive, di mappe del tempo trasmesse dai satelliti geostazionari e la possibilitá di consultare da host distribuiti su Internet le immagini sui laser disk del laboratorio di visualizzazione scientifica del CRS4.
Il gateway CCSO Nameserver/WWW : PHGATE
Questo semplice programma realizzato in linguaggio PERL [cite other:PERL] ha permesso l'implementazione di uno strumento di Phone Book per WWW, in particolare per il programma client XMosaic.
L'idea è quella di interrogare con parole chiave un Nameserver sviluppato nei laboratori CCSO (Computer and Communications Services Office - University of Illinois, Urbana), per ottenere record di dati di tipo anagrafico prelevati da un database relazionale. Il filtraggio dei dati restituiti dal Nameserver e la costruzione di una pagina report in forma HTML costituiscono le funzioni principali di PHGATE. PHGATE intercetta le richieste di connessione al Nameserver (attivo su una determinata porta della macchina) generando una cover page che informa l'utente delle operazioni necessarie per interrogare il database. L'utente a questo punto digita la parola chiave che viene passata al Nameserver. Il risultato della ricerca sfocia nella produzione di uno stream di records attinenti con la parola chiave. Questi ultimi vengono filtrati da PHGATE per essere ricondotti in forma HTML ed essere visualizzati. La possibilitá di inserire accanto ad ogni record restituito dal Nameserver un'immagine ( ad es. una fotografia in formato GIF del soggetto), è data da particolari funzioni di HTML che consentono di importare questi file all'interno dell'area di visualizzazione di XMosaic .
Il risultato finale è dato dalle seguenti figg.5 e 6.
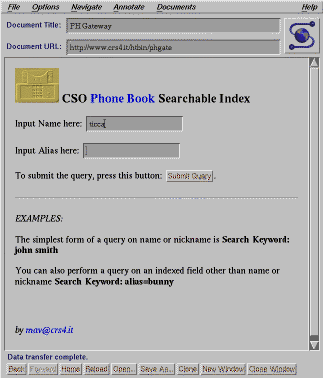
La visualizzazione della cover page di Phone Book
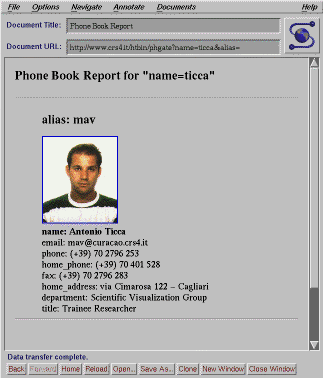
Il risultato di una ricerca per keyword
Questo esperimento realizzato in seno al CRS4 si colloca in uno scenario che prevede la produzione di documenti dinamici in formato HTML direttamente dalla sorgente di informazione.
L'idea è implementare un programma server che aggiorni in tempo reale un archivio di dati (agenda) con notizie riguardanti seminari, meetings eventi ecc. in programma al CRS4. Il server opera in due fasi. Nella prima fase vengono generati i documenti in forma HTML dopo aver intercettato i messaggi informativi inviati attraverso il mail server. Questi messaggi vengono redatti in formato LaTeX e vengono inviati sotto forma di e-mail agli utenti. Una volta filtrati da LaTeX a HTML, i documenti vengono riordinati cronologicamente secondo la data dell'evento in un archivio locale.
La seconda fase consiste nella creazione di pagine di calendario in base alle richieste dell'utente. Le pagine di calendario vengono visualizzate come delle liste strutturate ciascun elemento delle quali punta all'annuncio generato in precedenza.
L'iter che l'utente segue per interrogare l'Event Schedule è illustrato dalle figure seguenti.
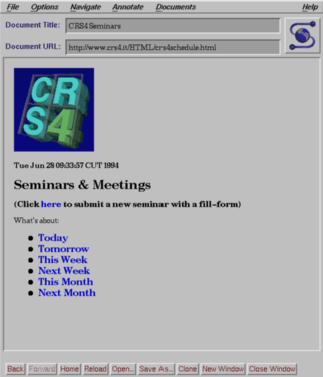
L'utente ha a disposizione diverse scelte per richiamare le pagine del calendario
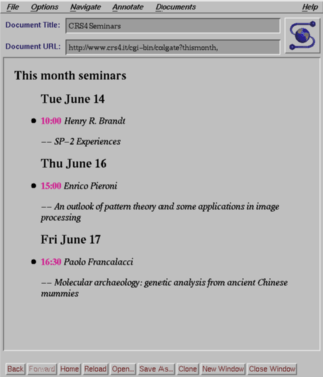
Una tipica pagina di calendario è costituita da una lista di entry ciascuna delle quali punta all'abstract
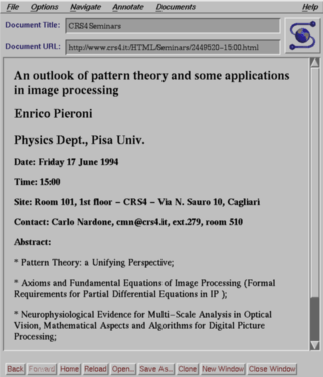
Il documento con l'abstract del seminario cosi come appare all'utente
Gli Electronic Preprints (EPS) costituiscono una enorme massa di informazioni accessibili all'utente generico attraverso i vari Mail Server. Questi sono versioni preliminari di articoli scientifici la cui stesura avviene convenzionalmente in formato TeX o LaTeX. Gli EPS risiedono in database pubblici distribuiti su Internet strutturati in maniera gerarchica secondo argomenti trattati e date di pubblicazione; essi vengono aggiornati periodicamente ed il loro accesso è consentito per il recupero degli elenchi e degli articoli che vengono spediti automaticamente sotto forma di e-mail.
Si puó vedere subito che un tale sistema di accesso alle informazioni non consente una cernita degli articoli di interesse se non dopo aver trasferito nella propria mailbox anche intere directory di documenti, causando un accumulo di dati non banale.
L'idea base è quella di poter accedere in tempo reale al server per leggere gli elenchi degli articoli ivi contenuti e da questi poter puntare all'articolo stesso in modo diretto.
L'articolo viene trasferito localmente (con FTP) solo dopo essere stato selezionato dall'elenco. Infine viene compilato per essere ricondotto in forma PostScript ed essere visualizzato con Ghostview (vedi figg. seguenti).
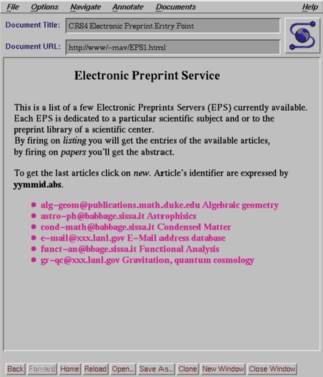
La cover page per gli EPS
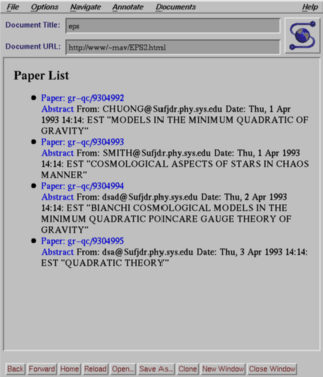
Un'elenco degli articoli contenuti in un Electronic Preprint Site
Come si è potuto vedere, una delle soluzioni dei problemi connessi al trattamento della enorme massa di informazioni disomogenee in ambienti distribuiti di tipo wide-area, coinvolge un'architettura nella quale è implementato un sistema di filtraggio delle informazioni per ricondurle, quando è possibile, ad un unico formato.
Oltre a ció, sia l'attivazione delle connessioni con i vari server preposti al mantenimento delle informazioni, in ambito locale e no, sia le modalitá di colloqio con questi ultimi, sono demandati ad un unico programma interfacciato con essi.
In ultima analisi, uno strumento come quello descritto sopra, permette la visualizzazione delle informazioni on-fly, senza cioé trasferirle fisicamente da remoto. Questo implica la possibilitá di salvare sulla propria home solo dati utili.
Attualmente sono allo studio nuovi moduli da integrare all'architettura aperta di WWW. Questi sono rivolti al trattamento dei suoni e dei dati scientifici in formato HDF e TH [cite other:TH] che permetteranno di ricevere e processare i dati generati dalle simulazioni scientifiche portate avanti dai vari centri di ricerca.
[other:Andre93] M.~Andressen. Ncsa mosaic technical summary. NCSA University of Illinois at Urbana, May 1993.
[other:Albe91] L.~Alberti, A.~Nome, P.~Salsiccio, and R.~Tui. Notes on internet gopher protocol. University of Minnesota, Dec 1991.
[other:Bern91] T.~Bernes-Lee. Http as implemented in www. CERN, Dec 1991.
[other:Bern92] T.~Bernes-Lee. World-wide-web: An information infrastructure for high-energy physics. CERN, Jan 1992.
[other:GoldF] C.~GoldFarb. Information technology- hypermedia/time based structuring language (hytime). ISO/IEC CD 10744 (Draft).
[other:Ha_Sw] F.~Halasz and M.~Schwartz. The dexter hypertext reference model. Proceedings of the Hypertext Standardization Workshop, National Institute of Standards and technology, Jan 1990.
[other:Kahl90] B.~Khale. Wais interface prototype functional specification. Thinking Machine Corporation, Apr 1990.
[other:Kant86] B.~Kantor and P.~Lapsley. A proposed standard for the stream-based transmission of news. Internet RFC-977, Feb 1986.
[other:TH] A.~Leone, L.~Filippini, and G.~Zanetti. Time history technical report. CRS4 Cagliari, 1993.
[other:Pome92] P.~Pomes. The ccso nameserver- a description. University of Illinois at Urbana, Aug 1992.
[other:Post85] J.~Postel and J.~Reynolds. File transfer protocol (ftp). INternet RFC-959, Oct 1985.
[other:SGML] SGML. Information processing text and office systems standard generalized markup language (sgml). ISO 8879:1986, 1986.
[other:PERL] L.~Wall and R.~Schwartz. Programming perl. O'Reilly and Associates, Inc., 1991.